Building an AI Agent Platform in Go with Clean Architecture
Most AI agent stacks today are built in Python.
That makes sense. Python has mature frameworks such as LangChain, LangGraph, and LlamaIndex, and the surrounding ecosystem is optimized for experimentation. But in my case, I ended up building an AI agent platform in Go, with almost everything implemented from scratch.
This article explains why I made that choice, how the initial implementation broke down as the system grew, and how I redesigned it around Clean Architecture. I will also cover the thread-based chat model, database design, persistence strategy, and the practical trade-offs I ran into while moving from “it works” to something that can actually live inside a product.
Why build an AI agent platform in Go?
The first reason was practical rather than ideological: the backend of the product was already written in Go.
For an MVP, introducing a separate Python service would have increased deployment, review, and operational complexity. It was cheaper to keep everything inside the existing Go backend and move fast there first.
Once I started building, I also realized that Go has several properties that are surprisingly well suited to AI agent infrastructure:
- goroutines make concurrent execution simple
- SSE, WebSocket, and gRPC are lightweight to implement
- deployment is easy because a single binary is often enough
- interfaces make abstraction boundaries explicit
- testability is high when dependencies are cleanly separated
Go does not have the same quantity of agent tooling as Python, so the implementation cost is somewhat higher. But the upside is that you get much tighter control over architecture, persistence, observability, and long-term maintainability.
Why not just use LangGraph or LlamaIndex?
Part of the reason is timing: I had already started building the MVP directly in Go.
But there was also a structural reason. In a previous product, I built an AI agent system on top of LangGraph Platform and found that some aspects of product integration were more constrained than expected. For example:
- internal state tends to become a black box
- persistence and thread management often need to follow framework conventions
- models and tools are coupled to framework-specific abstractions
- partial adoption is harder than it looks
- export, logging, and auditability can become awkward
Frameworks are useful, especially when the goal is fast prototyping. But when AI becomes a long-lived feature inside an existing backend, I care a lot about being able to control how messages are stored, how tools are executed, how streaming is handled, and how everything can later be exported or audited.
So instead of treating the agent framework as the center of the system, I wanted the product architecture to remain the center, and the agent layer to stay thin and replaceable.
Why Clean Architecture fits AI agents well
AI agent systems change constantly.
The model changes. The prompt format changes. Tools are added and removed. Memory strategies evolve. Streaming requirements shift from SSE to WebSocket or gRPC. Retrieval pipelines get replaced. Planner-executor patterns come and go.
That means the real challenge is not “how to call an LLM API.” The real challenge is how to isolate change.
This is exactly where Clean Architecture helps.
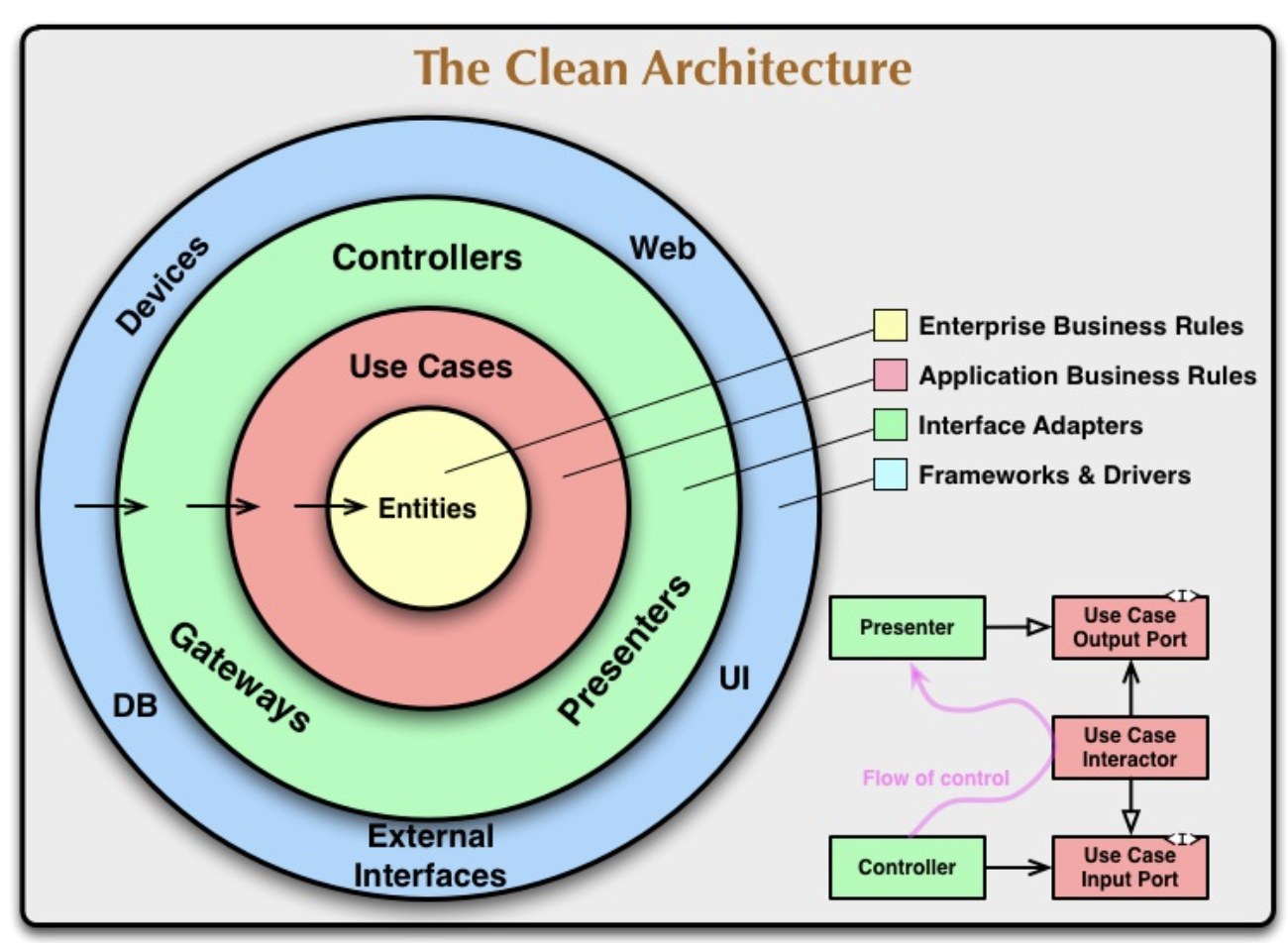 Source: The Clean Architecture – Robert C. Martin (Uncle Bob)
Source: The Clean Architecture – Robert C. Martin (Uncle Bob)
In my design, the core agent concepts are separated into abstractions such as:
- Model: OpenAI, Anthropic, local LLMs
- Memory: in-memory, PostgreSQL, Redis
- Tool: external API calls, DB lookup, computation, search
- Agent: ReAct-style execution, workflow-based agents, planner-executor
- Streaming: SSE, WebSocket, gRPC
By keeping these concepts behind interfaces, I can change the implementation without breaking the application layer. That means:
- switching from OpenAI to another provider does not force large refactors
- adding or removing tools stays localized
- changing memory from in-memory to persistent storage does not rewrite agent logic
- changing the transport from SSE to WebSocket does not require redesigning the agent itself
For AI systems, that flexibility matters more than almost anything else.
Before: a monolithic /api/ai/chat
The first version was intentionally simple.
There was a single endpoint, /api/ai/chat, and it did almost everything:
- bind the request
- build the prompt
- register tools
- call OpenAI
- stream the response back via SSE
At the MVP stage, this was the right choice. It minimized code and made the whole behavior easy to trace. One file gave you the entire flow.
Conceptually, the structure looked like this:
POST /api/ai/chat
↓
[Presentation]
ChatHandler
├─ request binding
├─ prompt building
├─ tool registration
└─ agent execution
↓
[Application]
ReactAgent
├─ OpenAI call
├─ tool execution
├─ state handling
└─ streaming
↓
[Domain]
prompt/context helpers
↓
[Infrastructure]
OpenAI client
PostgreSQL repository
This version was good enough to validate the feature.
But it quickly ran into structural problems.
Problems with the first version
1. The application layer was effectively tied to OpenAI
The OpenAI SDK was directly embedded into application logic. That meant changing the model provider was not just a matter of replacing one implementation. It affected multiple layers:
- application logic
- agent behavior
- response handling
- error handling
Instead of “the system supports OpenAI,” the actual state was “OpenAI is baked into the system.”
2. Tools were tightly coupled to concrete implementations
The tool registry and the individual tools were too close to application logic. Some tools directly touched repositories. Some depended on model-specific data shapes. That made it harder to:
- unit test tools independently
- reuse tools across agents
- evolve toward other tool protocols such as MCP
3. Streaming was hardcoded around SSE
Because the system was designed around SSE from the beginning, changing the output transport later would require touching a lot of code from the handler down into the agent execution flow.
Even before there was a concrete need for WebSocket or gRPC, I could already see the architectural problem: streaming details had leaked too far inward.
4. Testing was painful
Because the application layer depended directly on the OpenAI SDK, tool implementations, and memory implementations, mocking one thing tended to drag the others with it.
In practice, that pushed the code toward integration-heavy testing, even when what I really wanted was much simpler: mock Model, Memory, and Tool dependencies and verify only the agent behavior.
That was the point where I decided the agent system needed a real architectural boundary.
The redesign: move the agent core into pkg/ai
The key idea of the redesign was simple:
Put the core AI abstractions into a dedicated package and keep providers, persistence, and transport details outside of it.
The resulting structure looked roughly like this:
pkg/ai/
agents/ // Agent abstraction and ReactAgent
memory/ // Memory abstraction
models/ // Model abstraction
openai/ // OpenAI implementation
prompts/ // prompt abstractions
streaming/ // StreamEvent / StreamWriter abstractions
tools/ // Tool / ToolRegistry abstractions
types.go // Message / ToolCall / TokenUsage
application/
ai/tools/ // app-specific tools
usecases/ // AgentRunUsecase / ThreadUsecase / ThreadChatUsecase
infra/
ai/memory/ // PostgreSQL memory
ai/tools/ // default tool registry
ai/streaming/ // SSE writer, etc.
presentation/
handlers/ai/ // HTTP handlers
This is essentially a thin, self-owned agent layer inside a Go backend.
It plays a role similar to a lightweight internal version of LangChain, but built to fit the product’s own architecture instead of forcing the product to fit a framework.
Model abstraction
The first step was to hide provider-specific behavior behind a Model interface.
type Model interface {
Generate(
ctx context.Context,
messages []ai.Message,
opts ...ai.ModelOption,
) (*Response, error)
}
type StreamingModel interface {
Model
GenerateStream(
ctx context.Context,
messages []ai.Message,
opts ...ai.ModelOption,
) (<-chan streaming.StreamEvent, error)
}
This separates two concerns cleanly:
- the application and agent only know they are calling a model
- provider-specific code lives elsewhere
The OpenAI-specific implementation is isolated inside pkg/ai/openai, which is responsible for:
- converting internal messages into OpenAI request messages
- converting tool definitions into the provider’s function-calling format
- converting streaming output into internal stream events
That means the rest of the system does not need to know anything about the OpenAI SDK.
Memory abstraction
Conversation history is handled through a Memory interface.
type Memory interface {
LoadHistory(ctx context.Context, opts ...ai.MemoryLoadOption) ([]ai.Message, error)
Save(ctx context.Context, msg ai.Message) (*ai.StoredMessageInfo, error)
Clear(ctx context.Context) error
}
At first, I used an in-memory implementation. Later I replaced it with PostgreSQL-backed persistence.
The important point is that the agent does not know whether messages are being stored in memory, in Postgres, or somewhere else. It just loads and saves messages through the interface.
That makes memory strategy a replaceable concern rather than a structural dependency.
Tool abstraction
Tools represent the agent’s interface to the outside world.
type Tool interface {
Name() string
Description() string
JSONSchema() map[string]any
Call(ctx context.Context, args json.RawMessage) (any, error)
}
type ToolRegistry interface {
Register(tool Tool) error
Get(name string) (Tool, error)
List() []Tool
Execute(ctx context.Context, name string, args json.RawMessage) (any, error)
}
This lets the system split responsibilities cleanly:
pkg/ai/toolsdefines the abstraction- infrastructure provides the registry implementation
- application code provides product-specific tools
That separation turned out to be important. Product tools often need domain repositories or business rules, but the agent core should not know about those directly.
The agent itself: a ReAct-style execution loop
The agent depends only on abstractions:
ModelMemoryToolRegistryStreamWriter
That means the agent logic can focus only on the execution pattern.
In my case, I implemented a ReAct-style loop:
- load history from memory
- inject a dynamic system prompt
- add the user message
- call the model
- if the model requests tool calls, execute them and append the tool results to history
- call the model again
- if a final answer is returned, persist it and end the run
The agent does not know about HTTP. It does not know about SSE specifically. It does not know how PostgreSQL works. It only knows how to orchestrate message flow, tool calls, and stopping conditions.
That boundary was the most valuable part of the redesign.
Moving from single-shot chat to thread-based chat
A major change in the second phase was to stop treating chat as a one-off request and start modeling it as a real thread.
I introduced three core domain entities:
- Agent: the agent definition and configuration
- Thread: a conversation session
- Message: an individual item in the thread
This is a much better fit for product reality than a stateless /chat endpoint.
Agent
The Agent entity stores configuration such as:
- name
- description
- mode
- enabled tools
- model
- temperature
- max tokens
- timeout
- metadata
Thread
The Thread entity stores:
- ownership and tenancy
- associated agent
- title
- status
- metadata
- last message timestamp
Message
The Message entity stores:
- thread ID
- role (
user,assistant,system,tool) - structured content
- message order
- tool calls
- tool call IDs
- token usage
- timestamps
This model makes it possible to build a product-level chat system rather than a demo endpoint.
Database design
The database schema was intentionally simple:
agentsthreadsmessages
One design choice that mattered a lot was storing a message_index on messages.
That gave several advantages:
- ordering is explicit instead of depending on timestamps
- loading the latest N messages is easy
- future features such as insertion or editing are more manageable
This sounds like a small detail, but in chat systems, stable ordering becomes more important as soon as you care about persistence, debugging, or replay.
Replacing in-memory history with PostgreSQL memory
Once the thread model existed, the next step was to back memory with PostgreSQL.
The Postgres implementation does two main things:
Loading history
It retrieves messages belonging to a thread, ordered by message_index, and converts them into internal ai.Message objects.
One detail I intentionally added was excluding system messages from persistence-based reloads. System prompts are dynamically generated each run, so I did not want to treat them like ordinary stored history.
Saving messages
When saving, the implementation:
- assigns the next
message_index - handles tool call IDs
- determines message visibility
The visibility concept turned out to be useful. For example:
- user-visible messages can be shown in the end-user UI
- internal tool outputs and intermediate assistant messages can remain hidden from the user but still be available for debugging or auditing
That gives a much cleaner separation between what the agent actually does and what the product UI should expose.
Use cases and handlers
Once the abstractions existed, the application layer became much simpler.
The AgentRunUsecase is responsible for orchestration:
- resolve app-specific context
- construct the tool registry
- register the tools relevant to that use case
- build the model using a model factory
- build the agent
- execute it
In other words, the use case chooses which parts to assemble, but it does not contain the actual agent logic.
The presentation layer is thinner still. A handler only needs to:
- validate the request
- perform authentication
- create a stream writer
- delegate to the appropriate use case
That means HTTP concerns remain HTTP concerns, and AI concerns remain AI concerns.
This separation is exactly what I wanted from the beginning, but could only get after introducing explicit abstractions.
Practical pitfalls during implementation
The redesign improved the architecture, but it did not eliminate implementation traps.
Here are two of the most important ones.
1. User messages were accidentally saved twice
At one point, both the use case and the agent were saving the same user message:
- the use case saved it before execution
- the agent saved it again after loading history and appending the user input
The fix was straightforward once I understood the responsibility boundary:
All agent-managed messages — user, assistant, tool, and system-related internal flow — should be saved by the agent side through memory. The use case should not duplicate that responsibility.
2. Streaming responses were not being persisted
When streaming token deltas directly to the client, you do not automatically get a final assistant message to store.
So the agent had to explicitly accumulate the streamed text:
- collect every text delta into a buffer
- keep streaming those deltas to the client
- once the stream finishes, if the result is a final answer rather than a tool call, save the collected text as one assistant message
Without this step, the UI would show the answer live, but the database would not actually contain the final response.
That kind of issue is easy to miss when the transport and the persistence logic are not clearly separated.
What became easier after the redesign?
The biggest improvement was not elegance. It was local change.
After the redesign:
- changing model providers became much more contained
- adding or removing tools no longer contaminated unrelated parts of the codebase
- changing memory implementation did not require rewriting agent logic
- streaming transport became a replaceable output concern
- agent behavior became testable without HTTP
- use-case level orchestration became clearer
In practice, this changed the development loop.
Instead of experimenting directly inside handlers or endpoint logic, I could iterate freely inside pkg/ai, and only later wire the results into application and presentation layers.
That made both experimentation and stabilization easier.
What I still think are the trade-offs?
I do not want to oversell this approach.
Building a thin, self-owned agent layer in Go is not the fastest way to get an AI feature on the screen. If you only want a demo, or if the system will never become a core product feature, using an existing framework can absolutely be the better choice.
The trade-off is simple:
- framework-first gives faster short-term development
- architecture-first gives better long-term control
If your AI functionality needs to live inside an existing Go backend, be persisted cleanly, be audited, be observable, and evolve over time, then the architecture-first route becomes much more attractive.
Future extensions
The design also leaves room for further growth.
RAG
RAG can be added in at least two ways:
- as tools, such as
SearchDocumentsTool - as a retrieval step inside memory loading
Because both ToolRegistry and Memory are abstracted, either approach can be introduced later without destabilizing the rest of the agent layer.
Multi-provider models
A ModelFactory interface makes it straightforward to support multiple providers:
- OpenAI
- Anthropic
- local LLMs
This can later expand into per-agent model selection or even dynamic model routing.
MCP and external tool protocols
Because tools are already abstracted, an MCP-backed tool layer can be integrated by:
- implementing MCP-aware tools
- or synchronizing remote tool definitions into the registry
From the agent’s point of view, they are still just tools.
Conclusion
The most important lesson from this project is that building AI agents for products is much more about system design than about LLM API calls.
The hard parts are:
- isolating provider dependencies
- structuring tool execution
- designing memory correctly
- deciding what gets persisted
- handling streaming without leaking transport details everywhere
- keeping the system testable while the AI stack keeps changing
For my use case, Go and Clean Architecture turned out to be a very good combination for solving those problems.
Python still dominates the AI tooling ecosystem, and for good reasons. But if your product backend is already in Go, and you want an AI agent system that behaves like a real product subsystem instead of a framework-shaped add-on, building a thin internal agent layer in Go is a very practical option.
It is slower at first.
But it gives you control where it matters.